
Introduction
In today’s digital age, personalized recommendations drive engagement. From Netflix suggesting your next watch to Amazon’s “Customers who bought this also bought…”, recommender systems shape our choices. But how do they work? By analyzing user interactions, they uncover hidden patterns. In this article, we’ll explore their mechanics and implement them using real-world movie data.
Types of Recommender Systems
Recommender systems can be broadly categorized into four main types: Popularity-based, Content-based filtering, Collaborative filtering, and Hybrid approaches. Each method has its own strengths and challenges, which we will explore in detail below.
Popularity-based approach
Recommends popular items based on overall engagement, not individual preferences. Ideal for suggesting trending movies, best-selling books, or top-streamed songs where personalization isn’t needed.
Collaborative filtering approach
Suggests items based on user or item similarities (user-based or item-based CF). However, it struggles with the cold start problem when new users or items lack data. Netflix addresses this by asking new users to rate movies upfront, enabling better initial recommendations.
Content-based filtering approach
Analyzes item attributes like genres and features to recommend similar content based on user preferences. This helps with cold start issues but may cause over-specialization, limiting diversity. For example, a sci-fi fan might only get sci-fi recommendations. Spotify avoids this with features like ‘Discover Weekly,’ which introduces fresh yet relevant content.
Hybrid approach
Combines multiple techniques to leverage their respective strengths. For instance, a hybrid model might:
- Recommend trending movies based on overall engagement (popularity-based).
- Offer highly rated movies enjoyed by users with similar preferences (collaborative filtering).
- Suggest movies with similar genres to those a user has previously liked (content-based).
This ensures recommendations are both personalized and diverse, avoiding issues like over-specialization or cold start problems.
Context-aware approach
Uses external factors like time, location, device, or mood to refine recommendations in real time. For example, a streaming service might suggest upbeat music during a morning commute and relaxing shows at home in the evening, making recommendations more dynamic and relevant.
Building a Hybrid Recommender System
We’ll develop a Hybrid recommender system using the MovieLens dataset, progressing from basic to advanced techniques. First, we perform Exploratory Data Analysis (EDA) to examine data structure, detect missing values, and identify trends. Visualizing ratings reveals user preferences and biases, ensuring a solid foundation for model selection.
rating = pd.read_csv('/kaggle/input/movielens-20m-dataset/rating.csv')
movie = pd.read_csv('/kaggle/input/movielens-20m-dataset/movie.csv')
print(rating.info())
print(movie.info())
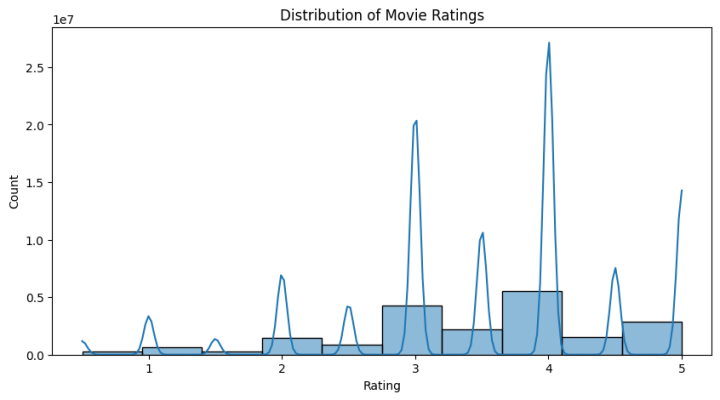
sns.histplot(rating['rating'], bins=10, kde=True)
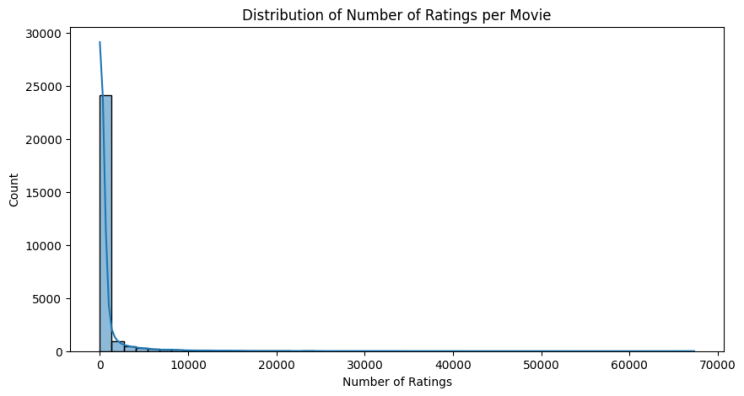
sns.histplot(rating['movieId'].value_counts(), bins=50, kde=True)
Popularity-based approach
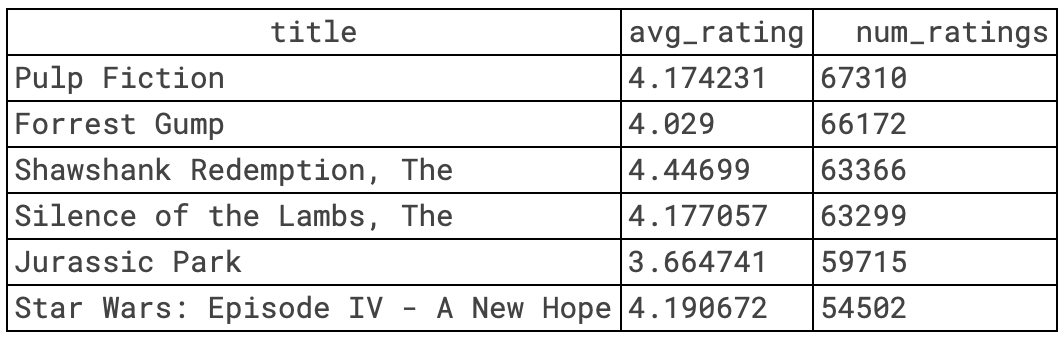
To implement this, we first aggregate user ratings to compute the average rating and number of ratings for each movie. Since movies with very few ratings may not be reliable indicators of popularity, we apply a popularity threshold—for example, only considering movies with at least 50 ratings. Finally, we rank movies based on the number of ratings and average score, ensuring that frequently rated and highly appreciated titles appear at the top.
# Aggregate Ratings
movie_ratings = rating.groupby('movieId').agg(
avg_rating=('rating', 'mean'),
num_ratings=('rating', 'count')
).reset_index()
# Merge with Movie Titles
movie_ratings = movie_ratings.merge(movie[['movieId', 'title']], on='movieId', how='left')
# Set a Popularity Threshold
threshold = 50 # Change as needed
popular_movies = movie_ratings[movie_ratings['num_ratings'] >= threshold]
# Rank Movies by Popularity
popular_movies = popular_movies.sort_values(by=['num_ratings', 'avg_rating'], ascending=[False, False])
# Display Top N Popular Movies
def get_top_popular_movies(n=10):
return popular_movies[['title', 'avg_rating', 'num_ratings']].head(n)
# Example Usage
print(get_top_popular_movies(10))
Content-based filtering approach
We preprocess genre data into a TF-IDF (Term Frequency-Inverse Document Frequency) matrix, a technique that assigns importance to words (or genres) based on their frequency in a dataset. TF (Term Frequency) measures how often a term appears in a movie’s genre list, while IDF (Inverse Document Frequency) reduces the weight of common genres across all movies, ensuring that rare genres are emphasized.
Next, we compute cosine similarity to find movies with similar genre profiles. For example, if a user likes Toy Story (1995), content-based filtering will recommend movies with similar genres. While this method personalizes suggestions, it can create a recommendation bubble, where users receive overly similar recommendations.
# Fill NaN values in genres
movie['genres'] = movie['genres'].fillna('')
# Convert genres to a TF-IDF matrix
vectorizer = TfidfVectorizer(stop_words='english')
tfidf_matrix = vectorizer.fit_transform(movie['genres'])
# Compute cosine similarity between movies
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
# Create a mapping of movie titles to indices
indices = pd.Series(movie.index, index=movie['title']).drop_duplicates()
# Function to get similar movies
def get_content_based_recommendations(title, n=10):
if title not in indices:
return "Movie not found."
idx = indices[title]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:n+1]
movie_indices = [i[0] for i in sim_scores]
return movie[['title']].iloc[movie_indices]
# Example Usage
print(get_content_based_recommendations("Toy Story (1995)", 10))

Collaborative filtering approach
Collaborative filtering personalizes recommendations by analyzing user-item interactions. Singular Value Decomposition (SVD) helps uncover hidden preference patterns by factorizing the user-item matrix. Using the MovieLens dataset, we train an SVD model with the Surprise library, splitting data into training and test sets. The trained model predicts ratings for unseen movies, generating personalized recommendations. Finally, we merge seen and recommended movies, providing a complete, tailored experience.
Besides SVD, collaborative filtering can use k-Nearest Neighbors (k-NN) for user-item similarity, ALS (Alternating Least Squares) and NMF (Non-negative Matrix Factorization) for matrix factorization, and deep learning-based methods like Neural Collaborative Filtering (NCF) and Autoencoders for capturing complex, non-linear user-item interactions. Graph-based approaches such as Random Walk with Restart (RWR) are particularly effective in social network-based recommendations, while Bayesian Personalized Ranking (BPR) is useful for optimizing implicit feedback models by learning from pairwise ranking comparisons.
# Loading and splitting data
reader = Reader(rating_scale=(0.5, 5.0))
data = Dataset.load_from_df(rating[['userId', 'movieId', 'rating']], reader)
trainset, testset = train_test_split(data, test_size=0.2)
# Train SVD model
svd = SVD()
svd.fit(trainset)
# Evaluate model
predictions = svd.test(testset)
print("RMSE:", rmse(predictions))
# Function to get movies already seen by a user
def get_seen_movies(user_id):
seen_movies = rating[rating['userId'] == user_id].merge(movie[['movieId', 'title']], on='movieId', how='left')
seen_movies['type'] = 'seen'
return seen_movies[['title', 'rating', 'type']].sort_values(by='rating', ascending=False)
# Function to get movie recommendations for a user
def get_collaborative_recommendations(user_id, n=10):
movie_ids = rating['movieId'].unique()
unseen_movies = [movie for movie in movie_ids if movie not in rating[rating['userId'] == user_id]['movieId'].values]
predictions = [(movie, svd.predict(user_id, movie).est) for movie in unseen_movies]
recommendations = sorted(predictions, key=lambda x: x[1], reverse=True)[:n]
recommended_movies = pd.DataFrame(recommendations, columns=['movieId', 'predicted_rating'])
recommended_movies = recommended_movies.merge(movie[['movieId', 'title']], on='movieId', how='left')
recommended_movies['type'] = 'recommended'
return recommended_movies[['title', 'predicted_rating', 'type']]
# Merge the seen and recommended datasets
seen_movies = get_seen_movies(1)
recommended_movies = get_collaborative_recommendations(1, n=10)
merged_movies = pd.concat([recommended_movies, seen_movies], ignore_index=True)
display(merged_movies.head(20))
Hybrid approach
To finalize our hybrid approach, we strategically combine popularity-based, content-based, and collaborative filtering methods, assigning weighted scores to each. By blending trending selections, personalized suggestions, and collaborative insights, we create a well-rounded recommendation system. This fusion mitigates over-specialization, enhances diversity, and ensures users receive both familiar favorites and fresh discoveries—striking the perfect balance between relevance and exploration.
# Hybrid Recommender with Weighted Scoring
def get_hybrid_recommendations_with_weights(user_id, user_favorite_movie, popularity_weight=0.33, content_weight=0.33, collaborative_weight=0.33, n=10):
# Get top popular movies
popular_movies = get_top_popular_movies(n)
popular_movies = popular_movies[['title', 'avg_rating']].copy()
popular_movies['score'] = popular_movies['avg_rating'] * popularity_weight # Weighted score
# Get content-based recommendations (assuming a fixed title, or adapt dynamically)
content_recs = get_content_based_recommendations(user_favorite_movie, n)
content_recs = content_recs[['title']].copy()
content_recs['score'] = content_weight # Assign content-based weight
# Get collaborative-based recommendations
collaborative_recs = get_collaborative_recommendations(user_id, n)
collaborative_recs = collaborative_recs[['title', 'predicted_rating']].copy()
collaborative_recs['score'] = collaborative_recs['predicted_rating'] * collaborative_weight # Weighted score
# Merge all recommendations using an outer join to retain unique titles
all_recs = pd.concat([popular_movies, content_recs, collaborative_recs], ignore_index=True)
# Group by movie title and sum scores from different recommendation sources
final_recs = all_recs.groupby('title', as_index=False).agg({'score': 'sum'})
# Sort by final weighted score
final_recs = final_recs.sort_values(by='score', ascending=False)
# Return the top n recommendations
return final_recs.head(n)
# Example Usage
user_id=1
user_favorite_movie="Toy Story (1995)"
print(get_hybrid_recommendations_with_weights(user_id, user_favorite_movie, popularity_weight=0.33, content_weight=0.33, collaborative_weight=0.33, n=10))

Closing Thoughts
Recommender systems are shaping digital experiences across industries—be it personalized movie suggestions, e-commerce recommendations, or even online learning. While basic models like popularity-based recommendations serve general audiences, advanced hybrid approaches provide tailored experiences that adapt to user behavior in real time.
As recommendation technologies evolve, emerging trends like deep learning-based recommenders (e.g., Transformers, Autoencoders) are pushing personalization even further. How do you see these systems shaping the future of your industry?
Framework code can be found here: Kaggle
Originally published on LinkedIn